简介
Service在Kubernetes官方主页是这样描述的:
Kubernetes Pod 是转瞬即逝的。 Pod 实际上拥有 生命周期。 当一个工作 Node 挂掉后, 在 Node 上运行的 Pod 也会消亡。 ReplicaSet 会自动地通过创建新的 Pod 驱动集群回到目标状态,以保证应用程序正常运行。 换一个例子,考虑一个具有3个副本数的用作图像处理的后端程序。这些副本是可替换的; 前端系统不应该关心后端副本,即使 Pod 丢失或重新创建。也就是说,Kubernetes 集群中的每个 Pod (即使是在同一个 Node 上的 Pod )都有一个唯一的 IP 地址,因此需要一种方法自动协调 Pod 之间的变更,以便应用程序保持运行。
Kubernetes 中的服务(Service)是一种抽象概念,它定义了 Pod 的逻辑集和访问 Pod 的协议。Service 使从属 Pod 之间的松耦合成为可能。来标记。
而我所理解的是:Service是一个抽象概念,类型微服务下的服务,它统一了同组POD对外访问的方式,类型传统架构下使用VIP访问后端多应用的结构。本片文章会从Service信息提交给kube-apiserver组件开始到我们能通过ClusterIP访问POD为结尾,详细了解Service运作原理。我们先从Service创建的流程开始。
环境
正文
创建过程
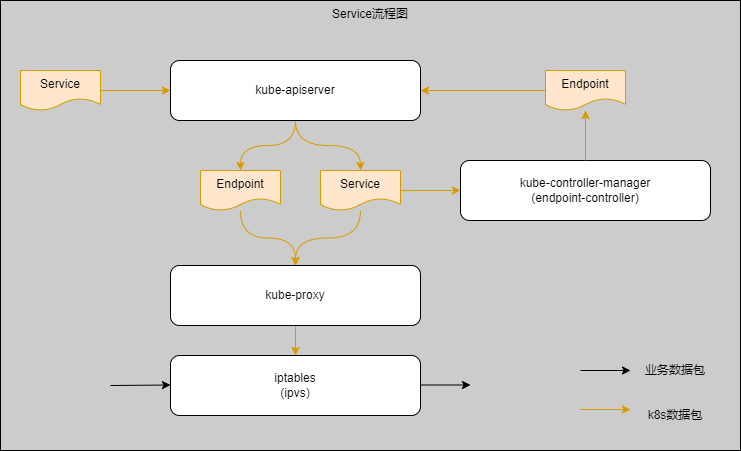
在我们提交Service对象给kube-apiserver组件后,kube-apiserver组件会把Service对象存储到etcd,并广播创建Service这条信息。这个时候kube-controller-manager组件与kube-proxy组件都监听到对象并做相应处理,注意这里是并发形式的。当kube-controller-manager组件监听到Service变更时(创建)会由endpoint-controller功能进行解析处理生成Endpoint资源对象并提交给kube-apiserver组件,而kube-apiserver组件会把Endpoint对象存储在etcd,并且广播创建Endpoint这条信息。同时kube-proxy组件也接收到了Service信息,kube-proxy组件监听到Service变更时(创建)会在iptables或ipvs(看具体kube-proxy采用的方式,后面具体会说明)创建有关ClusterIP的条目。具体如下图:
PS:
-
Service是工作在传输层(4层),所以也是4层负载
-
Service实现负载均Node需要满足如下三个条件:
- 容器之间能直接通信;
- 容器与Node之间能直接通信;
- 容器看到自身的IP和外面看到它的IP必须是一样的,即不存在IP转化的问题;
使用类型
- clusterIP:只能在集群的节点和pod中访问,解决的就是集群内应用间的相互访问的问题;
- nodeport:通过节点的地址和端口把pod暴露到集群外,让集群外的应用能访问集群内的应用,设置服务类型为nodeport时,是在clusterIP的基础上再给节点开个端口转发(是特定节点还是每一个节点要看externalTrafficPolicy的值,Cluster是每一个节点都开,Local是只在pod运行的节点开),所以nodeport的服务也会有一个clusterIP
- loadBalancer:因为使用nodeport方式时,免不了要在应用的调用方写死一个集群节点的IP,这并非高可用的方式,所以又有了使用第三方负载均衡器的方式,转发到多个节点的nodeport,这种类型通常需要用户扩展个控制器与云平台或所属IDC机房的负载均衡器打通才能生效,普通安装的k8s集群一般类型为loadBalancer的服务都是pending状态;loadBalancer是在nodeport的基础之上再创建个lb,所以也是会先分配一个clusterIP,再创建节点的端口转发。
- headless:应用内多个副本彼此间互相访问,比如要部署到mysql的主从,从的副本想要找主的副本;
- externalName:其实只是相当于coredns里的cname记录
原理模拟
$ sysctl –write net.ipv4.ip_forward=1